


Chain of Draft: Thinking Faster by Writing Less
Chain of Draft demonstrates that effective reasoning in LLMs does not necessarily require length outputs, offering an alternative approach where reasoning depth is maintained with minimal verbosity...

In this article, I explore Chain of Draft prompting strategy and highlight its key differences from the well-known Chain of Thought approach.
I first came across this prompting technique through
and (I highly recommend you to follow them, also you can follow ’s newsletter: ). After learning about it, I read the corresponding scientific paper to gain a deeper understanding and decided to share my insights in this article. Credit goes to them for introducing me to this concept.The research paper for this new prompting technic was recently published (on the 25th of February 2025), which you can find on [2502.18600] Chain of Draft: Thinking Faster by Writing Less. In this article, I summarize its key aspects, but I encourage you to read the original paper for a more in-depth exploration.
Chain of Thought (CoT)
Before diving into Chain of Draft (CoD) prompting, it's essential to understand Chain of Thought (CoT), as the two techniques are closely related. You can think of CoD as a more efficient refinement of CoT, designed to address some of its limitations.
Chain of Thought prompting encourages LLMs to break down their reasoning step by step before arriving at an answer. This approach is particularly useful for solving problems that require logical thinking or multi-step reasoning. Essentially, it gives the model "time to think" allowing it to generate a structured, step-by-step response.:
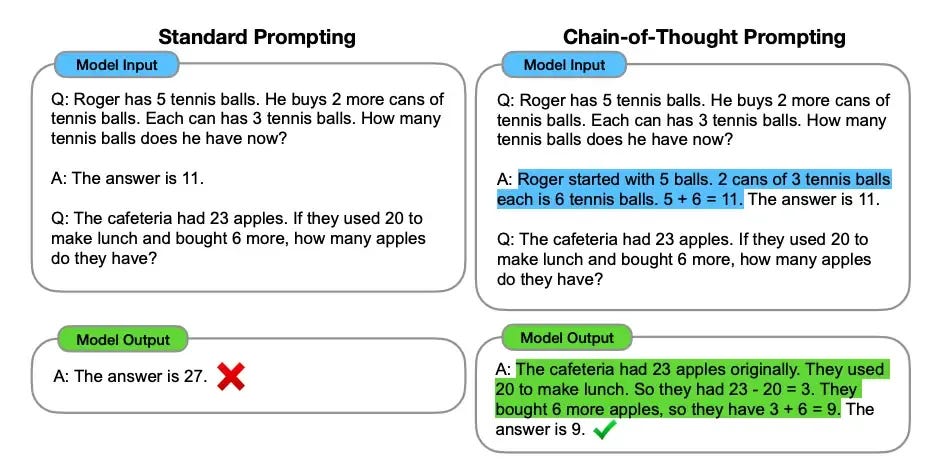
As shown in the figure above, this prompting technique is effective for breaking down complex questions into manageable steps, guiding the LLM to approach problem-solving in a way similar to human reasoning.
You can check out my previous article to see some of the most common prompting techniques.
This approach is inspired by how humans tackle complex problems, such as arithmetic, mathematical reasoning, or coding challenges. However, because it relies on a "write-and-think" methodology, it significantly increases computational demands during inference, resulting in more verbose outputs and higher latency.
For example, CoT prompting can be applied to a mathematical problem like this:
In this example, rather than directly jumping to the solution (as we explicitly specify), the LLM breaks down the problem into smaller, manageable steps. It then follows a logical path to solve the problem. While this approach is effective, it often results in lengthy outputs, which in turn causes increased latency.
Given that LLMs have token limits based on both input and output tokens, this can quickly consume output tokens even when not necessary. This is where Chain of Draft (CoD) prompting comes into play, offering a more efficient alternative.
Chain of Draft (CoD)
Chain of Draft (CoD) is a new prompting technique introduced by four AI researchers at Zoom — Silei Xu, Wenhao Xie, Lingxiao Zhao, and Pengcheng He — on February 25, 2025.
CoD demonstrates that effective reasoning in LLMs does not necessarily require length outputs, offering an alternative approach where reasoning depth is maintained with minimal verbosity.
The core idea behind this approach is inspired by how humans externalize their thoughts. When solving complex tasks, a person doesn’t write down every single thought; instead, they focus on recording only the critical pieces of information that drive progress. Similarly, CoD allows the LLM to take time before providing an answer.
However, rather than breaking down the problem in exhaustive detail, it encourages the model to focus on the key points that are most critical to solving the problem:

You can see the output for the same question we asked in the previous section using Chain-of-Thought prompting. The output is much smaller, which helps preserve output tokens and resolve the latency issue.
As highlighted in the paper, this prompting strategy delivers on its promise: "Thinking Faster by Writing Less."
Here is a good image that compares these two prompting strategies:

Why CoD Matters?
This new prompting strategy offers several key benefits:
Reduces latency
Cost effective (significantly less output generated)
Comparable or even superior accuracy
However, despite these advantages, it’s important to note that CoD is not a one-size-fits-all solution. To gain a better understanding, it’s helpful to summarize the key takeaways for both prompting techniques.
Key Takeaways
The Chain of Draft (CoD) prompting inspired by human cognitive processes. When solving problems rather than elaborating on every detail, humans typically jump into the essential intermediate results - minimal drafts (as described in the paper) - to facilitate their thought processes.
CoD is especially useful if you want to inimize output tokens while solving complex problems that require reasoning.
In CoD, the general approach is to limit each reasoning step to a specific number of words at most, and let LLM to get to the essential point. This aims to maintain latency issue and lengthy of outputs.
On the other hand, the Chain of Thought (CoT) prompting technique is still valuable when solving a complex problem where you may not have prior knowledge and need more detailed steps to arrive at a solution. Additionally, if there are no limitations on output tokens, CoT remains a viable option.
As shown in the benchmark results from the scientific paper, there is no significant difference in accuracy between these two approaches, but CoD results in a substantial reduction in latency:

Arithmetic Reasoning (GSM8K) 
Commonsense Reasoning (BIG-bench) In some cases, CoD even demonstrates better accuracy results. Additionally, it's important to note that there is nearly a 4x reduction in latency between these two approaches.


Conclusion
Chain of Draft (CoD) prompting proves to be highly beneficial for real-time applications where both cost and speed are critical. Additionally, the results from the paper show that there is no significant difference in accuracy compared to Chain of Thought (CoT).
When comparing these two prompting strategies in terms of token usage, the difference is substantial:

Also, CoD encourages LLMs to generate concise, information-dense outputs at each step. As described, it's based on how humans externalize their thoughts, making the output feel more natural and aligned with our expectations.
Thank you for reading! I’d love to hear your thoughts on this new prompting strategy, so please feel free to share them in the comment section. See you in the next one!